深入理解 CLH Queue Lock
详解CLH队列锁的设计原理、实现机制及其在Java并发编程中的应用,为理解AQS和JUC同步原语奠定基础
JUC 包中的很多同步原语是基于 AbstractQueuedSynchronizer(以下简称 AQS) 实现的,而 AQS 的实现又是基于 CLH 队列锁(CLH queued lock),因此学习并理解 CLH 队列锁对我们学习 JUC 中的各种同步原语非常有帮助。本文将阐述 CLH 队列锁的实现和原理。
CLH Queue Lock #
CLH 队列锁是由 Craig, Landin, Hagersten 三位大佬提出的,因此被称为 CLH 队列锁,它是一种自旋公平锁,基于虚链表实现(virtual linked list)。
《The Art of Multiprocessor Programming》7.5.2 节给出了 CLH 可能的一种 Java 语言实现:
public class CLHLock implements Lock {
AtomicReference<QNode> tail;
ThreadLocal<QNode> myPred;
ThreadLocal<QNode> myNode;
public CLHLock() {
tail = new AtomicReference<QNode>(new QNode());
myNode = new ThreadLocal<QNode>() {
protected QNode initialValue() {
return new QNode();
}
};
myPred = new ThreadLocal<QNode>() {
protected QNode initialValue() {
return null;
}
};
}
public void lock() {
QNode qnode = myNode.get();
qnode.locked = true;
QNode pred = tail.getAndSet(qnode);
myPred.set(pred);
while (pred.locked) {
}
}
public void unlock() {
QNode qnode = myNode.get();
qnode.locked = false;
myNode.set(myPred.get());
}
class QNode {
volatile boolean locked = false;
}
}
接下来将会对源码以及其中各个关键技术进行分析。
数据结构 #
QNode #
class QNode {
volatile boolean locked = false;
}
QNode 记录一个线程的同步状态,它只有一个实例字段 locked ,其含义为:
true:表示该线程要么已经拿到了锁,要么等待获取锁false:表示该线程已经释放了锁。
Virtual Linked List #
CLHLock 类中有三个实例字段,共同构成了 CLH 队列锁的虚队列结构:
AtomicReference<QNode> tail:指向最后加入虚队列的线程节点ThreadLocal<QNode> myPred:每个线程独有,指向该线程的前继节点的QNodeThreadLocal<QNode> myNode:每个线程独有,指向线程自己的QNode
tail 节点是始终指向虚队列的尾结点,即最后加入队列的线程节点。因其是 AtomicReference 类型,因此对其的操作都可以保证是原子性的,不会造成线程不安全的问题。
而之所以称 CLH 队列锁的数据结构是一个虚队列,是因为每个线程只能通过 prev 节点访问到它的前继节点,链表结构对我们来说是『隐式』的。
We use the term “virtual” because the list is implicit: Each thread refers to its predecessor through a thread-local pred variable.
CLH 队列是根据线程请求锁的顺序来进行排列的,因此是 First-in-first-out 的,满足公平锁的定义。
加锁 #
public void lock() {
// 获取当前线程的 QNode
QNode qnode = myNode.get();
// 将 myNode.locked 置为 true,表示当前线程想要获取锁
qnode.locked = true;
// 通过 tail 获取队列末尾的线程 QNode
// 并且更新 tail 节点指向当前线程,CAS 操作保证原子性
// 现在当前线程排到了队列的末尾
QNode pred = tail.getAndSet(qnode);
// 设置当前线程的前继节点 myPred
myPred.set(pred);
// 在 pred 上忙等待,直到前继节点将其 locked 更新为 flase
while (pred.locked) {
}
}
一个线程获取锁的步骤可以总结为:
- 将自己的
QNode状态置为true,表示自己想要获取锁。 - 将自己加入到虚队列的末尾(即让
tail指向自己的QNode),同时得到自己的前继节点的QNode,这是一个原子操作,由AtomicReference类型保证。 - 在前继节点
myPred的QNode上进行忙等待,直到前继节点释放锁为止。
解锁 #
public void unlock() {
// 获取当前线程 QNode
QNode qnode = myNode.get();
// 将其置为 false,表示当前线程离开临界区,并释放锁
qnode.locked = false;
// 循环利用 QNode,且防止该线程下次加锁时发生死锁
myNode.set(myPred.get());
}
线程解锁的步骤可以总结为:
- 获取当前线程的
QNode - 将当前线程的
QNode状态置为false,表示当前线程已经处理完临界区的工作,释放锁 - 更新
myNode引用,使其指向一个新的QNode对象,防止死锁。
死锁的可能性以及 QNode 的回收利用 #
可能有读者会奇怪这里为什么需要更新 myNode 引用,能不能不更新 myNode 引用,直接从方法调用中返回呢?
public void unlock() {
QNode qnode = myNode.get();
qnode.locked = false;
// 不更新 myNode 引用直接返回
// myNode.set(myPred.get());
}
如果不更新 myNode 对象,那么可能会出现如下的情况:
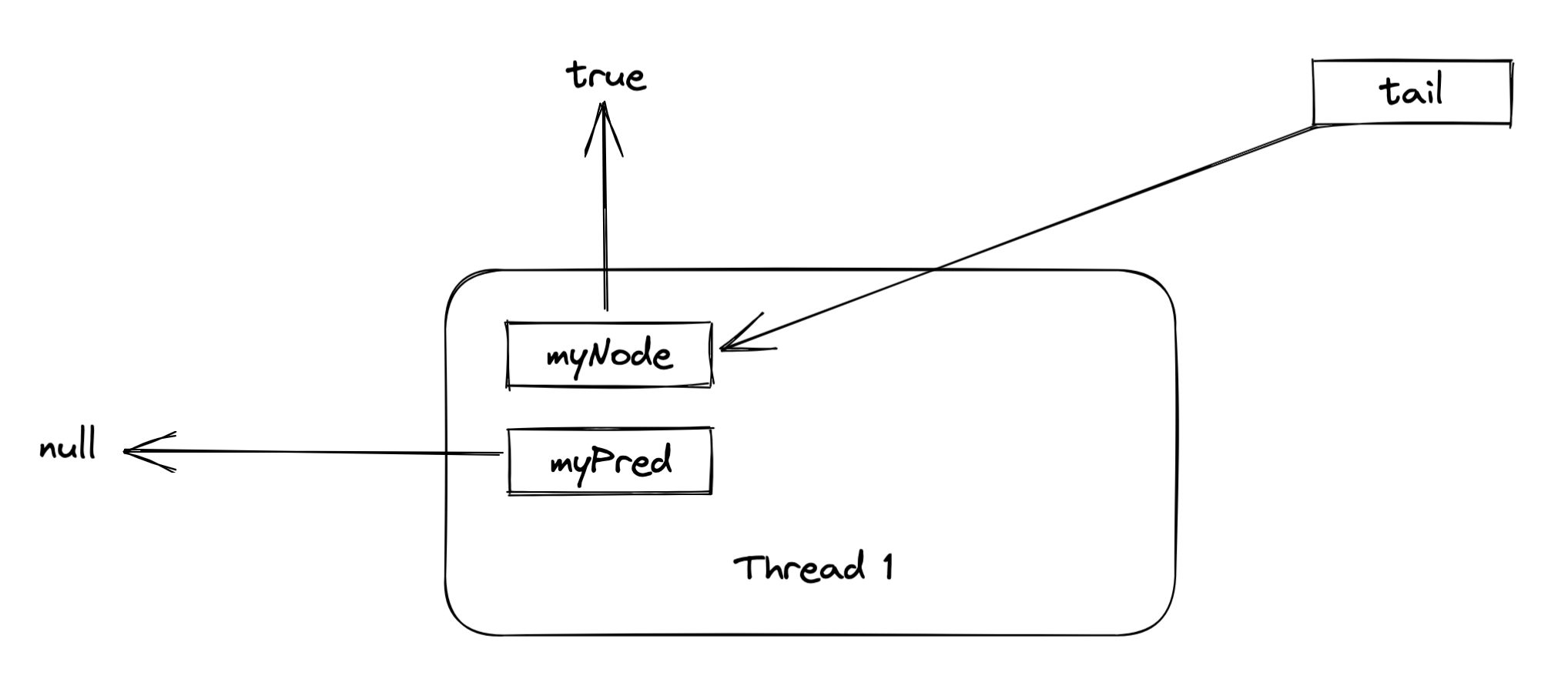
假设整个 CLH 队列中只有一个线程,它能够立刻获得锁(因为没有前继节点持有锁)并进入临界区。它在执行完临界区工作后释放了锁,将自己的 QNode 置为 flase ,那么将变成下图的情况:

之后,该线程立刻再次尝试获取锁,这个时候,CLH 队列的情况和上图是一致的,因为我们在解锁时没有更新 myNode 引用,那么 tail 节点和该线程的 myNode 节点指向的是同一个内存对象。那么考虑该线程重新尝试加锁时会发生什么:
public void lock() {
// qnode 即为上次加锁、解锁中使用的 QNode 数据结构
QNode qnode = myNode.get();
// 将 myNode.locked 置为 true
qnode.locked = true;
// 通过 tail 获取队列末尾的线程 QNode,tail 此时指向的对象既为该线程自己的 myNode
// 也就是上上条语句 QNode qnode = myNode.get(); 拿到的 QNode 引用
QNode pred = tail.getAndSet(qnode);
// 设置当前线程的前继节点 myPred,这个时候 myPred 指向了 myNode
// 也就是说该线程的前继线程是自己,明显是错误的
myPred.set(pred);
// pred.locked == myNode.locked && myNode.locked == true,死锁
while (pred.locked) {
}
}
通过注释可以清晰地看到,因为 tail 指向了想要重新获取锁的这条线程,那么这个线程的 myNode 和 myPred 将指向同一个对象,最终将永远忙等待下去。这也就是为什么我们需要在解锁时更新 myNode 的原因,这是为了让同一个线程再次加锁时不发生死锁而必要的一个操作。
而《The Art of Multiprocessor Programming》的实现中是将 myPred 直接赋值给了 myNode ,这是因为前继节点对应的线程已经离开了临界区,自然它的 QNode 就不会再被使用了,这里循环使用了内存中的对象。其实也可以重新实例化一个新的 QNode 并赋值给 myNode 也是可以的。《The Art of Multiprocessor Programming》的一条脚注说明了这一点:
There is no need to reuse nodes in garbage-collected languages such as Java or C#, but reuse would be needed in languages such as C++ or C.
总结 #
CLH 队列锁通过一个虚队列来维护想要获取锁的线程,每当一个线程想要获取锁时,CLH 将其放到队列的末尾,并让其获得它的前继节点(即排在它前面的线程)的 QNode 引用。一个线程通过在它的前继节点的 QNode 状态上进行自旋,判断它能否获取到锁。
CLH 队列锁的缺点是它在无缓存的 NUMA 架构机器上性能并不好。因为每个线程都自旋在另一个线程的 QNode 状态上,而另一个线程的 QNode 状态对象可能存放在另一个 CPU 的本地内存中,这将导致这种自旋操作将变得很慢。如果是在 SMP 架构的机器上,因为内存读取的开销是统一的,因此该算法的性能就很好。
Perhaps the only disadvantage of this lock algorithm is that it performs poorly on cacheless NUMA architectures. Each thread spins waiting for its predecessor’s node’s
lockedfield to becomefalse. If this memory location is remote, then performance suffers. On cache-coherent architectures, however, this approach should work well.